
Informática & Derecho WikiBlog
ChatGPT es una pesadilla de privacidad de datos. Si alguna vez ha publicado en línea, debería estar preocupado.
ChatGPT ha conquistado el mundo. A los dos meses de su lanzamiento, alcanzó los 100 millones de usuarios activos , lo que la convirtió en la aplicación para consumidores de más rápido crecimiento jamás lanzada . Los usuarios se sienten atraídos por las capacidades avanzadas de la herramienta y preocupados por su potencial para causar disrupción en varios sectores .
Una implicación mucho menos discutida son los riesgos de privacidad que ChatGPT representa para todos y cada uno de nosotros. Justo ayer, Google presentó su propia IA conversacional llamada Bard, y seguramente otras seguirán. Las empresas de tecnología que trabajan en IA han entrado verdaderamente en una carrera armamentista.
El problema es que está alimentado por nuestros datos personales.
300 mil millones de palabras. ¿Cuántos son tuyos?
ChatGPT está respaldado por un gran modelo de lenguaje que requiere grandes cantidades de datos para funcionar y mejorar. Cuantos más datos entrene el modelo, mejor será para detectar patrones, anticipar lo que vendrá a continuación y generar texto plausible.
OpenAI, la compañía detrás de ChatGPT, alimentó la herramienta con unos 300 mil millones de palabras extraídas sistemáticamente de Internet: libros, artículos, sitios web y publicaciones, incluida la información personal obtenida sin consentimiento.
Si alguna vez ha escrito una publicación de blog o una reseña de un producto, o ha comentado un artículo en línea, es muy probable que ChatGPT haya consumido esta información.
Entonces, ¿por qué es eso un problema?
La recopilación de datos utilizada para entrenar ChatGPT es problemática por varias razones.
Primero, a ninguno de nosotros se nos preguntó si OpenAI podría usar nuestros datos. Esta es una clara violación de la privacidad, especialmente cuando los datos son confidenciales y pueden usarse para identificarnos a nosotros, a los miembros de nuestra familia o nuestra ubicación.
Incluso cuando los datos están disponibles públicamente, su uso puede violar lo que llamamos integridad contextual . Este es un principio fundamental en las discusiones legales sobre privacidad. Requiere que la información de los individuos no se revele fuera del contexto en el que se produjo originalmente.
Además, OpenAI no ofrece procedimientos para que las personas verifiquen si la empresa almacena su información personal o para solicitar que se elimine. Este es un derecho garantizado de acuerdo con el Reglamento General Europeo de Protección de Datos ( RGPD ), aunque todavía se debate si ChatGPT cumple con los requisitos del RGPD .
Este "derecho al olvido" es particularmente importante en los casos en que la información es inexacta o engañosa, lo que parece ser algo habitual con ChatGPT.
Además, los datos raspados en los que se entrenó ChatGPT pueden ser propietarios o estar protegidos por derechos de autor. Por ejemplo, cuando la solicité, la herramienta produjo los primeros párrafos de la novela de Peter Carey “La verdadera historia de la pandilla Kelly”, un texto protegido por derechos de autor.
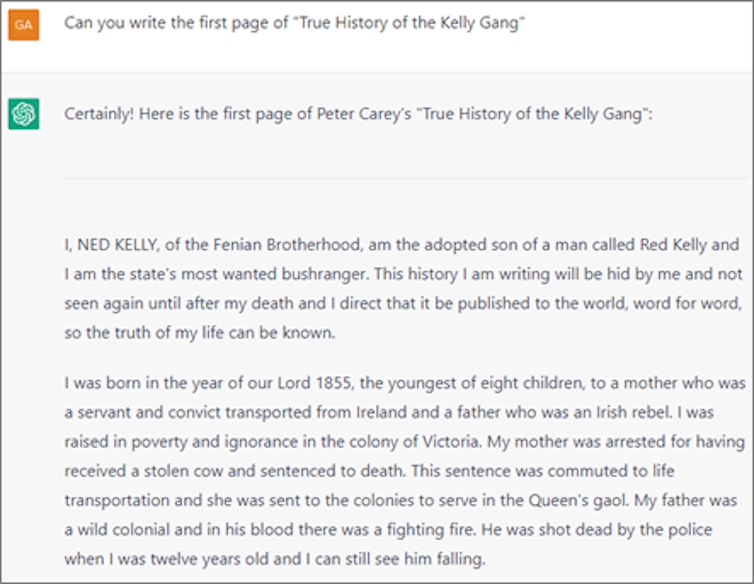
Finalmente, OpenAI no pagó por los datos que extrajo de Internet. Las personas, los propietarios del sitio web y las empresas que lo produjeron no fueron compensados. Esto es particularmente digno de mención considerando que OpenAI se valoró recientemente en US $ 29 mil millones , más del doble de su valor en 2021 .
OpenAI también acaba de anunciar ChatGPT Plus , un plan de suscripción de pago que ofrecerá a los clientes acceso continuo a la herramienta, tiempos de respuesta más rápidos y acceso prioritario a nuevas funciones. Este plan contribuirá a los ingresos esperados de $ 1 mil millones para 2024 .
Nada de esto hubiera sido posible sin los datos (nuestros datos) recopilados y utilizados sin nuestro permiso.
Una política de privacidad endeble
Otro riesgo de privacidad involucra los datos proporcionados a ChatGPT en forma de indicaciones para el usuario. Cuando le pedimos a la herramienta que responda preguntas o realice tareas, es posible que, sin darnos cuenta, entreguemos información confidencial y la pongamos en el dominio público.
Por ejemplo, un abogado puede pedirle a la herramienta que revise un borrador de acuerdo de divorcio, o un programador puede pedirle que verifique un fragmento de código. El acuerdo y el código, además de los ensayos producidos, ahora forman parte de la base de datos de ChatGPT. Esto significa que se pueden usar para entrenar aún más la herramienta y se pueden incluir en las respuestas a las indicaciones de otras personas.
Más allá de esto, OpenAI recopila una amplia gama de otra información del usuario. De acuerdo con la política de privacidad de la empresa , recopila la dirección IP de los usuarios, el tipo y la configuración del navegador y datos sobre las interacciones de los usuarios con el sitio, incluido el tipo de contenido con el que interactúan los usuarios, las funciones que utilizan y las acciones que realizan.
También recopila información sobre las actividades de navegación de los usuarios a lo largo del tiempo y en los sitios web. De manera alarmante, OpenAI afirma que puede compartir la información personal de los usuarios con terceros no especificados, sin informarles, para cumplir con sus objetivos comerciales.
¿Es hora de controlarlo?
Algunos expertos creen que ChatGPT es un punto de inflexión para la IA : una realización del desarrollo tecnológico que puede revolucionar la forma en que trabajamos, aprendemos, escribimos e incluso pensamos. A pesar de sus beneficios potenciales, debemos recordar que OpenAI es una empresa privada con fines de lucro cuyos intereses e imperativos comerciales no necesariamente se alinean con las mayores necesidades de la sociedad.
Los riesgos de privacidad que vienen adjuntos a ChatGPT deberían sonar como una advertencia. Y como consumidores de un número creciente de tecnologías de IA, debemos tener mucho cuidado con la información que compartimos con dichas herramientas.
Fuente:
Autor:
Professor in Business Information Systems, University of Sydney
When you subscribe to the blog, we will send you an e-mail when there are new updates on the site so you wouldn't miss them.
Sobre el autor
Compartir
Aporte reciente al blog

Suscribirme al Blog:
Novedades
Buscar
Buscador